2004-10-29
_ 仕事
0830 東陽町。
_ その「たん」
どこぞの ML でドリンク剤の話題になった( というかしたんだが )ときに「 リポビタン 」と書こうとして意図的に「 リポビたん 」と書いたら自分でウケてしまった。
_ なんてこった
昼飯に注文した黒ムツの定食のムツに火が通ってなかったのでごるん。
今朝出勤したら計算機のディスクがほげるしドリンク剤飲んでもふらふらするしツイてないしそれはそーと文が崩れてる気がする。
_ 逃亡中、探さないでください
という文が隣の席の私の雇い主の計算機のスクリーンセーバに書いてあった。
_ 仕事
2150 退勤。
_ ぐあ
アクビしたら腹筋だか肩あたりの筋肉がつった。
_ プログラムコードの行数を数える
Excel ファイルに書いてあるデータを awk やら sed やらを使って編集してごにょごにょして MS Word に張り付けて仕様書にするなどということをやってる。それなら始めから Excel な VBA でも使ったほうが楽だろうと思われるんだが、ぃゃほら VBA ってさっぱり使ってないから全然知らないしそれなら Excel Hacks でも買って勉強すればいいではないかと思うんだがあらためて買うのもなんだしなあというわけで結局「 UNIX プログラミング環境 」を読みながら awk なんぞを書いてたりする。
書籍や雑誌でプログラムコードを紹介するときに行番号が書いてある。こーいうのはどーやって出力してるんだろうと不思議に思っていたのだけど、とりあえず以下のようにすれば行番号を出力できることを発見した。
rin@sakura[~/public_html/diary]% awk '{ print NR, $0 }' index.rb | head
1 #!/usr/bin/env ruby
2 #
3 # index.rb $Revision: 1.26 $
4 #
5 # Copyright (C) 2001-2003, TADA Tadashi <sho@spc.gr.jp>
6 # You can redistribute it and/or modify it under GPL2.
7 #
8 BEGIN { $defout.binmode }
9 $KCODE = 'n'
10
コメントやら空行を除きたいときはこう。ちょっと長い。
rin@sakura[~/public_html/diary]% awk 'BEGIN{ ln = 1 } $0 !~ /^$|#.*/ { printf "%5d %s\n", ln++, $0 }' index.rb | head
1 BEGIN { $defout.binmode }
2 $KCODE = 'n'
3 begin
4 if FileTest::symlink?( __FILE__ ) then
5 org_path = File::dirname( File::readlink( __FILE__ ) )
6 else
7 org_path = File::dirname( __FILE__ )
8 end
9 $:.unshift( org_path.untaint )
10 require 'tdiary'
awk の printf は C の printf と同じ書式つき出力を使える。「 %5d 」と幅を指定してるのは行番号の桁数が増えたときの対処。最初に書いた出力だと幅を指定してないので 10 行目から右にひとつずれてしまってる。
もちろん対象としてるプログラミング言語のコメントが「#」以外の場合は適当に変える必要がある。
_ 連続データ
連続した値( 0000 から 1000 とか ) を作るときはいつも MS Excel を使って「 値を書いてそのセルの右下を右クリックしてにドラッグ 」して値を作ってる。
こんなやつ。
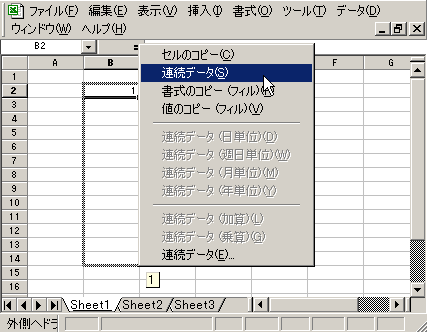
MS Excel のこの方法だと 16 進数の連続データなんぞが作れない。
それでいままで C でプログラムを書いて値を作っていた。こんな感じか。動作未確認。
#include <stdio.h>
int main( int ac, char** av )
{
int i;
for( i = 0; i < 16; i++ ) printf( "%02x", i );
printf( "\n" );
return 0;
}
awk だとこーいうに出来る。printf の書式が C のそのまま。awk は入力が必要らしいので最初に「 echo hello world 」なんぞやってる。
rin@sakura[~]% echo hello world | awk '{ for( i = 0; i < 16; i++ ) printf "%02x ", i; printf "\n" }'
00 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f
rin@sakura[~]%
あとは MS Excel だと行数が最大で 65536 までしかないので 65536 を超える値を作りたいときに良いんじゃないでしょか。